博主辛苦了,我要打赏银两给博主,犒劳犒劳站长。

【摘要】本文主要介绍一下聚类、增量聚类的主要概念,并提出了增量聚类算法等价性概念。
聚类[Clustering]是数据挖掘领域中最为常见的技术之一,用于发现在数据库中未知的对象类。通过聚类形成的每一个组称为一个类/簇[Cluster]。
多数聚类算法大体上可以分为以下几种:分割聚类方法,层次聚类方法,基于密度的聚类方法,基于网格的聚类方法和基于模型的聚类方法。但是就某个具体的聚类算法而言,往往是由多个聚类思想融合的结果,并不能简单地将其归入到上述某一类方法中。每种聚类算法都有各自的优点,同时也都存在一定的不足之处。
聚类分析的数据源————数据库中的数据通常是不断变化的,使得原聚类分析得到的聚类可能与新的数据不匹配。通常获得新的聚类的方法有两种:一是重新聚类;二是增量聚类。
聚类分析所面对的一般都是大数据集。所以如果是重新聚类的话,一方面是代价太大;另一方面是未利用前一次聚类所得到的相关信息,而导致计算资源的浪费。因此,如何设计增量聚类算法来提高聚类的效率,是当前聚类分析的一个最重要的挑战。
在设计增量聚类算法时,增量数据模型通常考虑两种:一是至今为止的所有数据,本文称之为全局数据模型FDM[Full Data Model];二是部分数据,如在时间窗口内的数据,本文称之为局部数据模型PDM[Part Data Model]。这两种增量数据模型对应于不同的应用需求。
增量数据模型如下图形象的表示:
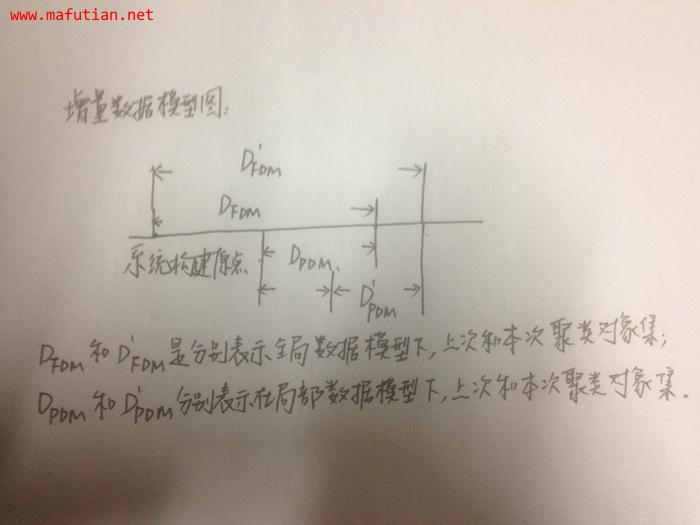
引起数据集变化的更新操作通常包括:插入、删除和修改。由于修改操作可以由删除和插入操作来实现[先删除、后插入],所以更新操作只考虑插入和删除两种。对于因插入、删除操作产生的增量数据集D1和D2,常用两种方式处理:[1]单个方式————每次处理一个数据;[2]批量方式————每次处理一批数据。这两种增量处理方式适应不同的应用需求,批量方式适用于更新的数据挖掘系统,而单个方式更适用于实时数据挖掘系统。
聚类分析中,判断聚类对象之间的相似性,是通过计算对象之间的差异度来实现的。在各聚类算法中,作为差异度的度量主要有距离和密度两种,其中以距离作为度量的居多。
对于增量聚类算法而言,有一个很重要的基本问题————算法等价性,即增量聚类算法的结果,与重新聚类的结果一致。但目前尚未见到证明某种基于距离的增量聚类算法具有等价性的文献。
版权归 马富天个人博客 所有
本文标题:《聚类、增量聚类的简介》
本文链接地址:http://www.mafutian.com/143.html
转载请务必注明出处,小生将不胜感激,谢谢! 喜欢本文或觉得本文对您有帮助,请分享给您的朋友 ^_^
顶0
踩0
| 评论审核未开启 |























|
||
|
|